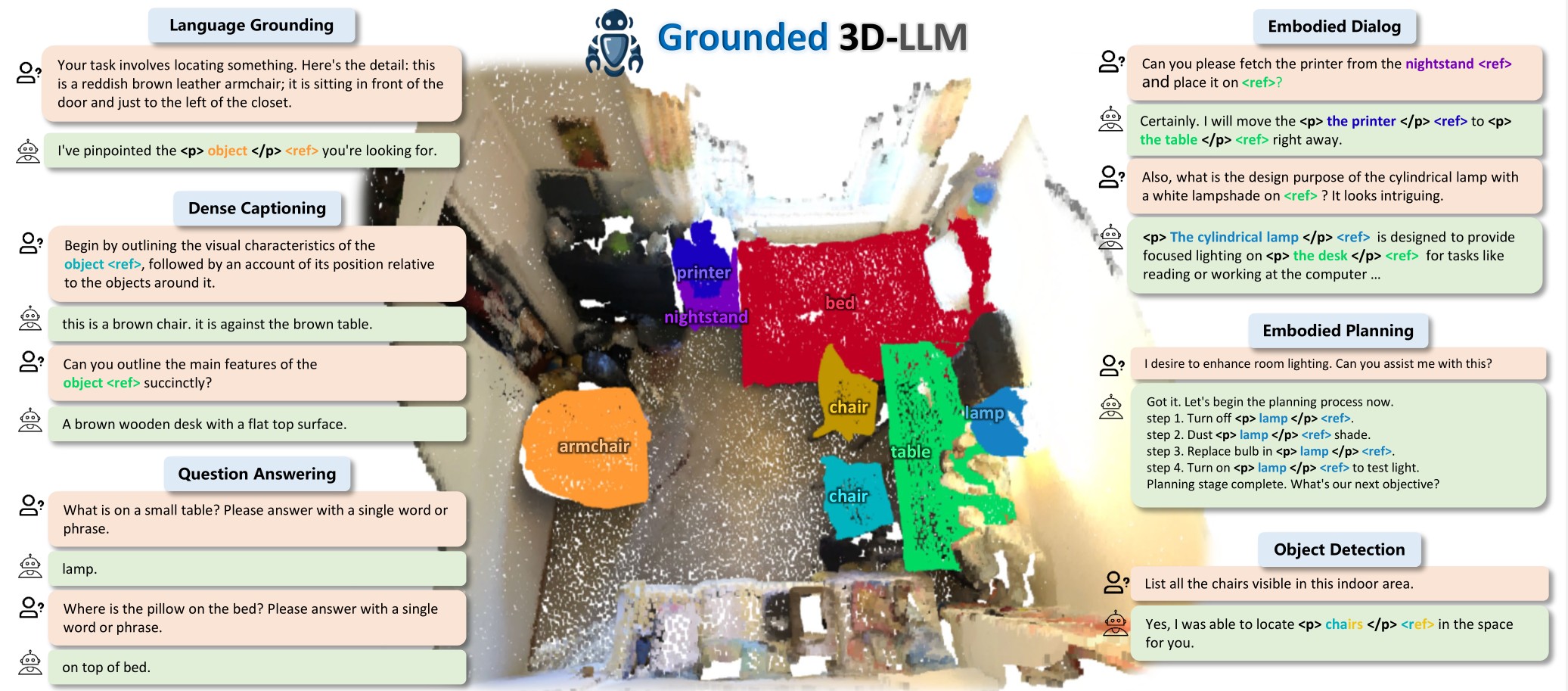
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling it to handle sequences that interleave 3D and textual data. Per-task instruction-following templates are employed to ensure natural and diversity in translating 3D vision tasks into language formats. To facilitate the use of referent tokens in subsequent language modeling, we provide a large-scale, automatically curated grounded scene-text dataset with over 1 million phrase-to-region correspondences and introduce Contrastive Language-Scene Pre-training (CLASP) to perform phrase-level scene-text alignment using this data. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D question answering, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM.
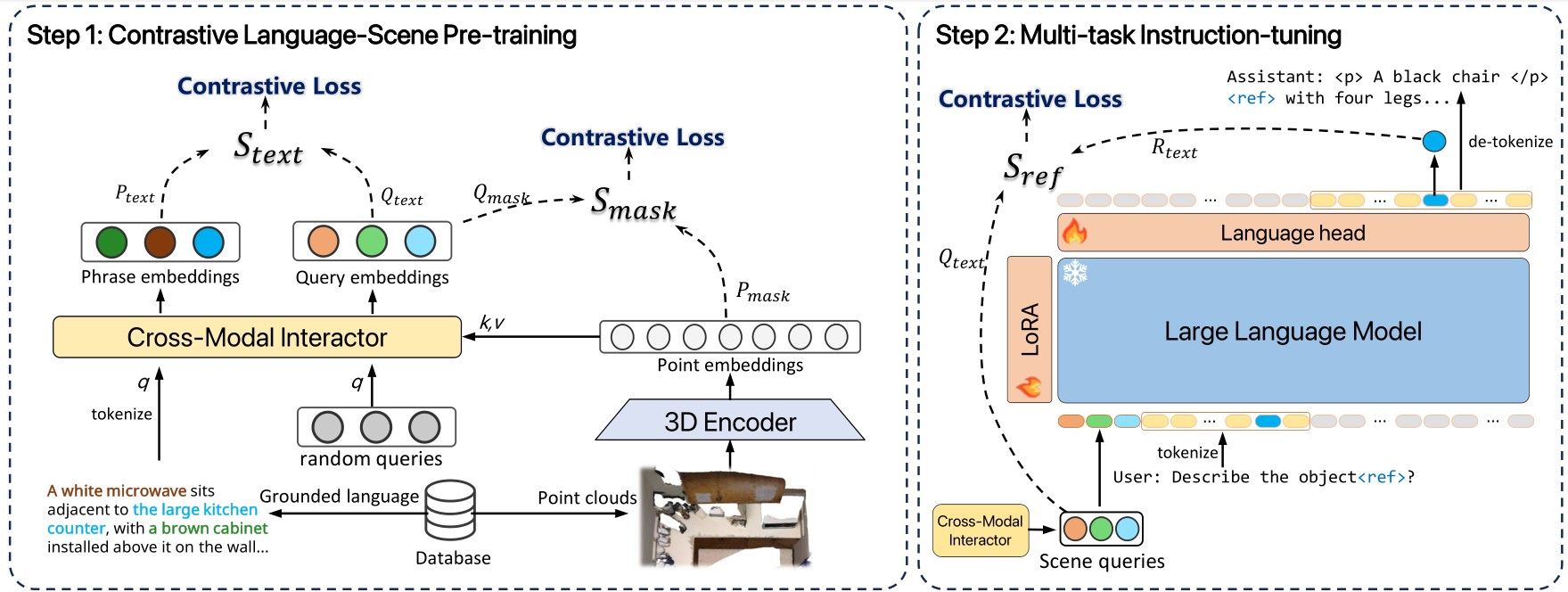
To reference phraseable objects in language modeling, a vision-language model is first pre-trained on large-scale grounded scene-text data to align text phrases with their corresponding 3D objects. Subsequently, a large language model (LLM) is fine-tuned using multi-modal instruction-following data, where referent tokens serve as interleaved soft text tokens representing the phraseable objects. Per-task instruction-following templates are employed to address the diverse range of 3D vision tasks within the unified language modeling framework.
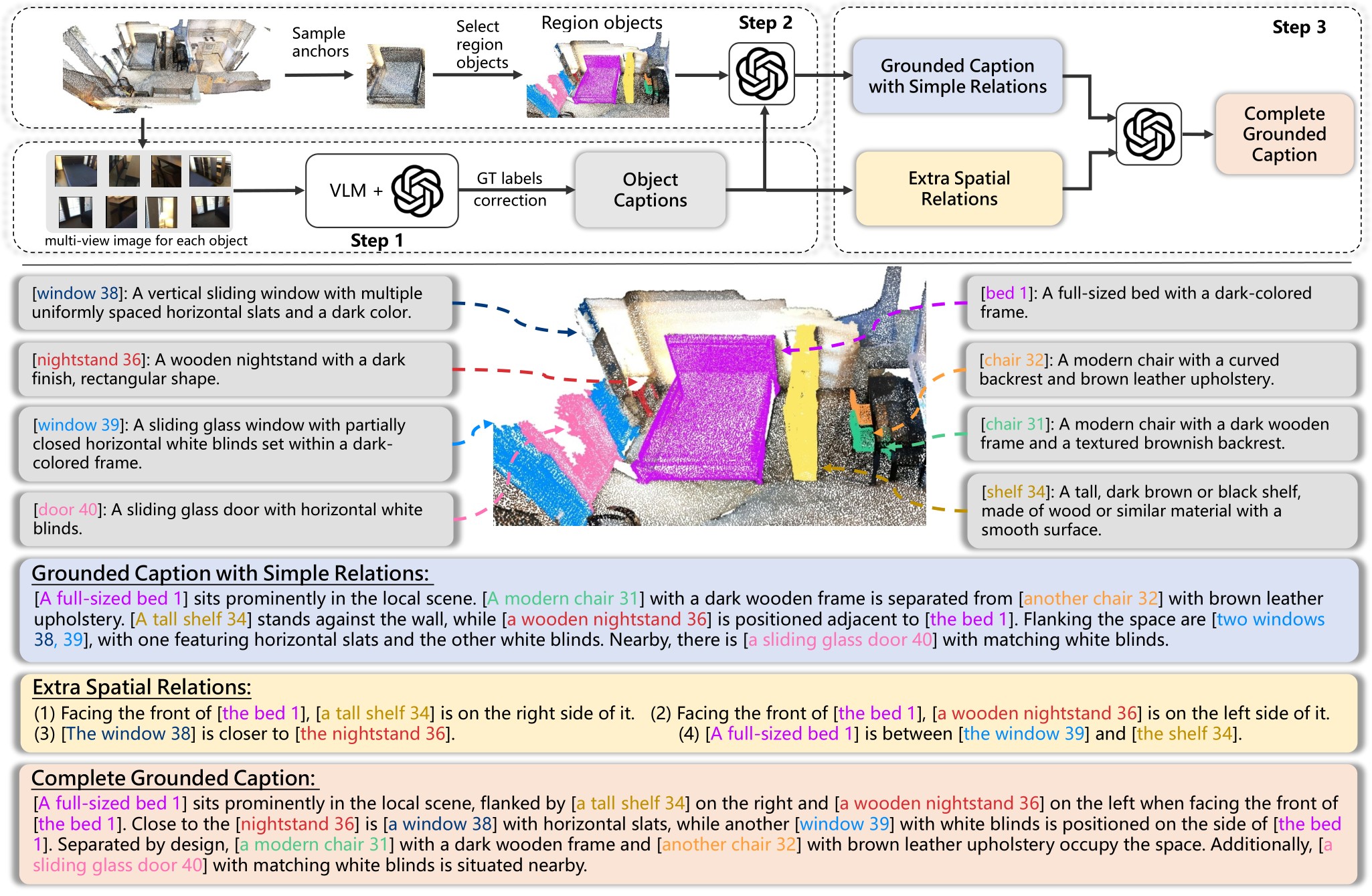
We propose an automated grounded language dataset generation process utilizing ChatGPT and 2D vision-language models to create the Grounded Scene Caption dataset (G-SceneCap):
For existing 3D vision-language tasks, we can transform them into instruction-following formats. These convertible 3D vision-language tasks include single and multi-object grounding, object detection, dense captioning, 3D QA, etc. For each task, we utilize approximately 10-20 structured task-specific instruction-following templates. Note that the referent correspondence is converted from the phrase-to-region correspondence of grounded scene-text annotation.

@article{chen2024grounded3dllm,
title={Grounded 3D-LLM with Referent Tokens},
author={Chen, Yilun and Yang, Shuai and Huang, Haifeng and Wang, Tai and Lyu, Ruiyuan and Xu, Runsen and Lin, Dahua and Pang, Jiangmiao},
journal={arXiv preprint arXiv:2405.10370},
year={2024},
}